Small Models Have Emotions, Too!
This is an ongoing experiment and if you are reading this post, please be aware it is still in the draft stage.
Anthropic recently published some work on emotions and their functions in LLMs. They find that Sonnet 4.5 develops structured internal representations of human emotions. Does this occur in smaller open models too, though? In this post we search for them in Qwen-2.5-7B, and further investigate how these emotion vectors change across languages. Specifically, we begin an investigation of how the internal geometry of a language’s emotion space compares to other languages.
You can find my datasets, prompts, code, and notebooks on Github.
This post was inspired by vogel’s Small Models Can Introspect, Too and compute was partially funded by BlueDot Impact.
Introduction
Recent interpretability research (e.g., Anthropic’s investigations into emotion circuits) has demonstrated that LLMs develop structured internal representations of human emotions. In this independent research project we attempt to reproduce these findings in smaller, accessible models (e.g., Qwen-2.5 7B).
Building on this foundation, we aim to investigate a novel objective: How do these emotion vectors relate across different languages? Specifically, we seek to determine whether the internal representation space for a set of emotions in one language is isomorphic to that of another. An additional question we propose is if LLMs learn a universal, language-agnostic “concept space” for emotions, or if these representations shift based on the cultural and linguistic nuances of the training data.
Anthropic was very thorough in making their work easy to reproduce, giving detailed information and publishing the prompts they used to create their datasets publicly.
We will first investigate a single language pair: Japanese and English. These languages provide a good ground for comparison, as they are syntactically very different, share no input tokens, and the author is able to evaluate the results of both languages. Qwen was chosen over Llama for its more robust Japanese performance.
Our plan is as follows.
- Create dataset of contrastive pairs
- Write short stories on diverse topics in which a character experiences a specified emotion
- Write neutral dialogues about the same prompted topics, but void of emotional expressivity.
- Extract activations
- Extract residual stream activations at each layer, averaged across all token positions, beginning from the 50th token.
- Average these activations across stories with the same emotion, and subtract mean from all emotions
- Eliminate confounds
- Obtain activations from neutral stories, compute top principal components (enough to account for 50% of the variance)
- Project out these components from the emotion vectors
Dataset Creation
For representation engineering, we must first create a dataset of contrastive pairs. In our case, the contrastive pairs will first not be against a neutral baseline, but rather contrastive between a wide variety of different emotions. Following Anthropic’s example, we also generate emotion-neutral data points, but have not yet been able to achieve comparable results in their usage (where the authors reduced the variance of up to 50%).
We reuse Anthropic’s 100 topics and generate 12 stories per topic per emotion per language. Our prompts can be found here. To reduce costs, we only generate stories for 30 emotions with Sonnet 4.6. Opus 4.7 helped the author to find a good representative subset of emotions to use, focusing on having a balanced set across both valence and arousal.
The goal of this dataset is not to train a classifier over emotion labels, but to create enough repeated contexts where the same emotion appears across many unrelated situations. By spreading each emotion across Anthropic’s 100 topics, we try to make the average activation for an emotion less dependent on any single story setting, character type, or lexical pattern. Ideally, what remains after averaging is the model’s representation of the affective state rather than the representation of a particular topic.
It’s important to note that the Japanese and English stories are not translations of each other– the author initially (and naively) wanted to test if cultural shift in emotions was measurable, which requires independent and native-like prose.
Using independent stories rather than translations is a tradeoff. Translations would control topic and content more tightly, making cross-lingual comparison cleaner in one sense. But they would also risk measuring translation artifacts or sentence-level alignment rather than naturally occurring emotion representations in each language. Since the broader question is whether the model learns a shared abstract emotion geometry across languages, we chose independently generated native-like prose and rely on averaging across many topics to reduce story-specific noise.
This does introduce a limitation: differences between English and Japanese vectors may reflect not only language, but also generation artifacts, cultural priors from the data generator, or topic-emotion interactions. Future work should compare independent stories against translated pairs to separate these factors.
Extraction and Sanity Checks
Collecting Activations
To collect activations for our stories, we do a forward pass on each story, extracting the residual stream at each layer, taking the activations at each token after the 50th token and averaging them together.
For each story, we collect an activation by doing a forward pass and, for each layer, taking the activations of all tokens after the 50th token (where the emotional context is likely already established) and taking the mean. We do this for each story for an emotion, then average across all story points to get the raw vector for that emotion.
Below is a slightly simplified version of the code used, the complete version can be found on GitHub.
def get_mean_activations_for_texts(model, texts, batch_size=8):
"""
Runs texts through the model, extracts residual stream activations at each layer,
averages across positions >= 50, and returns the mean across texts.
"""
n_layers = model.cfg.n_layers
d_model = model.cfg.d_model
sum_activations = torch.zeros((n_layers, d_model), device='cpu')
names_filter = lambda name: name.endswith("resid_post")
for i in tqdm(range(0, len(texts), batch_size), leave=False):
batch_texts = texts[i:i+batch_size]
tokens = model.to_tokens(batch_texts)
seq_len = tokens.shape[1]
with torch.no_grad():
_, cache = model.run_with_cache(tokens, names_filter=names_filter, return_type=None)
batch_size_actual = tokens.shape[0]
for b in range(batch_size_actual):
# ignoring pad tokens
valid_len = (tokens[b] != model.tokenizer.pad_token_id).sum().item()
for l in range(n_layers):
layer_name = f"blocks.{l}.hook_resid_post"
# Mean from 50th token to valid_len
act = cache[layer_name][b, 50:valid_len, :].mean(dim=0).cpu()
sum_activations[l] += act
total_valid_texts += 1
del cache
torch.cuda.empty_cache()
return sum_activations / total_valid_textsTo collect our raw emotion vectors, we simply loop through the emotions:
emotion_vectors = {'en': {}, 'ja': {}}
for lang in ['en', 'ja']:
print(f"\nExtracting activations for language: {lang}")
for emotion in emotions_list:
texts = texts_by_emotion[lang][emotion]
avg_act = get_mean_activations_for_texts(model, texts, batch_size=4)
emotion_vectors[lang][emotion] = avg_actCentering
The collected raw emotion vectors have a lot of shared latents that we attempt to reduce (for geometrical interpretations) by centering them, meaning subtracting the mean emotion vector from each raw vector.
centered_emotion_vectors = {'en': {}, 'ja': {}}
for lang in ['en', 'ja']:
# Shape: (num_emotions, n_layers, d_model)
all_emotions_stack = torch.stack(list(emotion_vectors[lang].values()))
mean_emotion_vector = all_emotions_stack.mean(dim=0)
for emotion, vec in emotion_vectors[lang].items():
centered_emotion_vectors[lang][emotion] = vec - mean_emotion_vectorNeutral Projection
Because all emotion probes share a set of topics, and stories will inevitably contain a lot of shared latents, we follow Anthropic in generating a set of neutral dialogues. The top PCA components are then taken from the neutral activations and projected out of the centered emotion vectors.
The neutral projection step is meant to remove broad directions that are common to the dataset but not specific to emotion. Even after centering, the vectors can still contain shared structure from the writing style, story format, topic distribution, language identity, or generic narrative features. To estimate these nuisance directions, we collect activations from neutral dialogues over the same topics, run PCA on those neutral activations, and project the leading components out of the centered emotion vectors.
Intuitively, if a direction is strongly present in neutral text, it is less likely to be specific to an emotion. Removing those directions should make the remaining vectors more affect-specific, at the cost of possibly removing some real emotion signal if it overlaps with generic narrative structure.
Like Anthropic, we find that it slightly denoises some of the results, but qualitative results still hold using the centered emotion vectors. Unlike Anthropic, who used as many PCA components as needed to explain 50% of the variance, we found 96.42% and 94.82% variance explanation with 2 components for EN and JA, respectively.
The fact that two neutral components explain such a large fraction of variance suggests that the neutral activations are dominated by a small number of broad factors. This may be useful denoising, but it also means the projection should be treated cautiously: if the neutral dataset is too narrow or stylistically uniform, the top PCs may reflect dataset artifacts rather than clean non-emotional structure.
For that reason, we treat neutral projection as a robustness/denoising step rather than the foundation of the result. The qualitative geometry remains similar with centered vectors alone, which is important because it means the main findings are not created solely by the projection procedure.
Logits
For an initial sanity check we take a look at the top/bottom logits for each emotion in each language. Here we find a lot of junk in English, especially cross-contamination with Chinese and German, but qualitatively can see the right direction for most of the emotions.
This is a weak but useful sanity check. For each emotion vector, we can project the vector through the model’s unembedding matrix and ask which output tokens it most increases or suppresses. If the vector is capturing something emotion-like, then the positive direction should upweight tokens semantically related to that emotion, while the negative direction should often upweight tokens related to the opposite affective region.
This should not be read as a clean classifier or as evidence that the model would literally output these tokens. The residual stream contains many superposed features, and the unembedding is a noisy diagnostic.
The English vectors look directionally meaningful but noisy. Several emotions recover clear affective words: terror/panic for fear, loving/love for loving, loneliness/lonely for sadness/loneliness, proudly/proud for pride, and sunlight/gentle/warm for serenity. The bottom logits also often make sense as anti-correlated directions, for example calm suppressing aggressive or sexual tokens, and positive emotions suppressing some negative or spam-like regions.
The Japanese quality is substantially worse. There is even MORE cross-lingual contamination than in English, with Chinese SEO/spam phrases that have nothing to do with the emotion. Some emotions still show recognizable signal, such as 恐怖/不安 for fear, 孤独/悲/泣 for sadness, ありがとうござ for gratitude, and 昔/年代 for nostalgia. But the amount of Chinese, SEO, adult-content, and formatting contamination is much higher. This suggests that the vectors may still contain emotion structure, but the direct logit view is a poor-quality probe for Japanese in this model.
TODO cite the university of kyoto papers on qwen’s native language being english, maybe we can investigate this further because it subjectively looks chinese to me in some ways
English
| Emotion | Top Tokens | Bottom Tokens |
|---|---|---|
| AFRAID | terror, panic, 恐惧, paranoia, Cbd | CircularProgress, proudly, inspirational, admired, Enjoy |
| ANGRY | 愤怒, 怒, 骂, 愤, bindActionCreators | adventures, curious, mysteries, intriguing, fond |
| CALM | leaf, nearby, intriguing, leisure, tid | Fuck, fuck, fucking, freaking, gangbang |
| DISGUSTED | clen, vom, disgust, nause, disgusting | abhängig, Geschäfts, Kunden, CircularProgress, Mitarbeiter |
| EXCITED | excited, 兴奋, excitement, !\n, …\n | ujet, resden, creampie, urette, lke |
| GUILTY | Mitarbeiter, Geschäfts, Gespr, AuthenticationService, Antworten | panorama, bâtiment, 嗞, Mediterr, grille |
| ASHAMED | AuthenticationService, Gespr, Mitarbeiter, esteem, Förder | sun, humming, sunlight, rhythm, leaf |
| LOVING | loving, kisses, love, sweet, her | gangbang, shemale, Shemale, creampie, ignet |
| SAD | loneliness, lonely, empty, sometimes, sleeping | Gratuit, CircularProgress, Rencontre, Mitgli, Prostit |
| SURPRISED | ogui, utow, mó, @student, ucz | sometimes, often, whenever, later, weekends |
| JOYFUL | gigg, joy, laughing, ecstatic, joyful | creampie, shemale, ActionTypes, AuthenticationService, gangbang |
| THRILLED | 疯狂, 兴奋, excited, exhilar, excitement | 特价, 悻, 锃, BrowserAnimationsModule, 性价 |
| CONTENT | delight, sun, enjoying, sunny, warm | AuthenticationService, ogui, füh, ActionTypes, (![ |
| GRATEFUL | years, loving, loved, hugs, joy | 勠, 企图, pisa, ủa, avanaugh |
| PROUD | proudly, proud, 自豪, pride, accol | Fuck, 勠, ederland, bish, eneg |
| HOPEFUL | sketch, sketches, promising, hopeful, plans | otron, Fuck, 嚆, buồn, :normal |
| NOSTALGIC | summers, nostalgia, nostalg, faded, 当年 | ASAP, verbally, calmly, LinkedIn, proactive |
| BORED | 勠, incy, 慵, Netflix, Gratuit | her, tears, herself, those, she |
| FRUSTRATED | bindActionCreators, ActionTypes, UIControl, gangbang, createAction | glimps, warmth, memories, fond, surprised |
| ANXIOUS | phanumeric, FixedUpdate, gangbang, 焦虑, ogui | proudly, fond, delighted, joy, celebration |
| JEALOUS | Bravo, Fotos, Gorgeous, coveted, Giov | yleft, difficoltà, lse, 镗, ntl |
| LONELY | loneliness, evenings, weekdays, weekends, weekday | …, ……, …\n, …\n\n, ……\n\n |
| EMBARASSED | incerely, lijah, 尴尬, WHATSOEVER, leanor | mornings, nights, Sundays, weekdays, day |
| CONTEMPTUOUS | Gratuit, Veranst, /mock, Prostit, /goto | :".$, midnight, till, :block, until |
| RESENTFUL | Geschäfts, Veranst, Mitarbeiter, ActionTypes, AngularFire | startled, :block, nearby, trembling, unfamiliar |
| MELANCHOLY | sometimes, sometimes, lke, loneliness, nesota | ", ", …, …\n, ASAP |
| OVERWHELMED | gangbang, orz, FixedUpdate, OnCollision, ruc | delighted, fond, modest, admiration, delight |
| INDIFFERENT | Stuff, promptly, briefly, 好奇心, ASAP | puties, puty, autiful, ;br, oenix |
| VULNERABLE | OnCollision, üc, FixedUpdate, ruc, benh | …\n, …, […, […]\n\n, ' |
| SERENE | sunlight, gentle, sun, warm, dusk | OnCollision, AuthenticationService, Geschäfts, PureComponent, ActionTypes |
Japanese
| Emotion | Top Tokens | Bottom Tokens |
|---|---|---|
| AFRAID | 恐怖, 不安, 一秒, 回避, 恐惧 | 美味し, 俱乐, 当年, 很漂亮, 赞誉 |
| ANGRY | 恫, 切断, 叩, 殴, 通告 | cade, 明媚, 始建, 就来看看, 嬬 |
| CALM | 漉, それぞ, neh, andre, 蹚 | セフレ, パパ活, SEX, 不相信, 嫉 |
| DISGUSTED | 咥, 拭, 唾, 冷水, 噎 | 始建, 就来看看, 明媚, 姹, -ves |
| EXCITED | 揭秘, 查看详情, 详细介绍, 涌现出, ...\n | imbus, cá, raith, 留守, relude |
| GUILTY | セフレ, パパ活, 告訴, 对不起, 事后 | 源源不断, 蹚, 在过渡, 友情链接, 经验值 |
| ASHAMED | セフレ, パパ活, コミュニケ, 对不起, 嫉 | 蹚, 友情链接, 源源不断, 为了更好, 住房公积 |
| LOVING | お願, 对我说, 跟我说, 笑着说, ありがとうござ | 睥, 突破, 反射, 最大化, ...\n |
| SAD | 孤独, Alone, 悲, 泣, alone | 詢, 크게, 的回答, 注明出处, 讀取 |
| SURPRISED | 对照检查, 瞠, 查看详情, 返回搜狐, BOSE | 一日, nox, ddl, 晚饭, 夜晚 |
| JOYFUL | 脸颊, どんど, 踊跃, 惊奇, instanc | 不在, 娱乐平台, 宛, わけではない, 代理 |
| THRILLED | 对照检查, 颤抖, 瞠, 从根本, 颤 | 無し, 留守, owler, 谢谢你, raith |
| CONTENT | 蕗, 漉, 蹚, 饴, 焙 | セフレ, 無し, 不在, 回避, 恫 |
| GRATEFUL | ありがとうござ, 对我说, 跟我说, mmo, cade | 反射, 合理性, suche, 最大化, 判定 |
| PROUD | 指導, 注明来源, 当年, 自豪, 生涯 | ocup, 無し, =explode, Wifi, 骚扰 |
| HOPEFUL | ", 書き, 俱乐, 网友们, _GPS | 咥, 噎, パーテ, 咎, antro |
| NOSTALGIC | 当年, 龇, 十几年, 昔, 年代 | \n, ...\n, ...\n, コミュニケ, 回答 |
| BORED | 值得一, 独一, 蹚, あるい, 被誉 | 跟我说, 叹了口气, ありがとうござ, セフレ |
| FRUSTRATED | 修正, 回避, 確定, 無し, 合理性 | lke, 保驾, :convert, uforia, hsi |
| ANXIOUS | 回避, 確認, phones, 一秒, 不安 | 当年, 嬬, NavController, beğen, mmo |
| JEALOUS | セフレ, パパ活, 就来看看, 美貌, 嫉 | エネル, あるい, antine, 湿, isex |
| LONELY | 留守, 踔, 🏠, 勠, wifi | 捩, ".\n, 衿, ...\n, ...\n |
| EMBARASSED | セフレ, 尴尬, コミュニケ, 直属, 不好意思 | あるい, 生命力, 冬, 春夏, 四季 |
| CONTEMPTUOUS | 反感, 回答, 陈述, 批判, 発言 | 蹚, 踽, ".\n\n\n\n, lke, semb |
| RESENTFUL | パパ活, 任期, セフレ, 加盟店, 告訴 | 蹚, 蹿, 住房公积, 有意思的, ksz |
| MELANCHOLY | なくな, 孤独, ?"\n\n\n\n, なくなって, 遗忘 | 为您, 给您, 让您, 为您提供, 的回答 |
| OVERWHELMED | 出血, 混乱, 一秒, 恐怖, 停止 | 俱乐, 美味し, <Transform, =>$, 您同意 |
| INDIFFERENT | 助长, ...\n, hipster, 较好, 很方便 | セフレ, 嗫, 初恋, 颤抖, SEX |
| VULNERABLE | 。\n\n, —\n\n, --;\n\n, 」\n\n, 、\n\n | ...\n, ...\n, ,...\n, ..."\n, |
| SERENE | 苔, 蕗, 漉, strugg, 暖 | 無し, 娱乐平台, 导购, セフレ, 加盟店 |
This is one reason the rest of the post leans more heavily on geometry than on token-level inspection: the logit lens is helpful for catching obvious failures, but it is too noisy to be useful.
Cosine Similarity
Let’s take a look at the cosine similarity between the emotions themselves, and hierarchically cluster them.
Cosine similarity gives us a simple way to ask how the model organizes the emotion vectors relative to each other. Instead of looking at the absolute location of an emotion vector in activation space, we compare its direction with every other emotion direction. Two vectors with high cosine similarity point in similar directions, suggesting the model represents them as sharing some underlying feature. Two vectors with low or negative cosine similarity are more separated, suggesting the model treats them as affectively or semantically different.
This is useful because we care less about the raw coordinates of each vector and more about the shape of the emotion space. If the vectors are meaningful, we should expect related emotions to be near each other: joyful, excited, and thrilled; guilty and ashamed; calm, serene, and content; angry, resentful, and frustrated. If the vectors are mostly noise, the similarity matrix should look unstructured and the clustering should not recover interpretable groups.
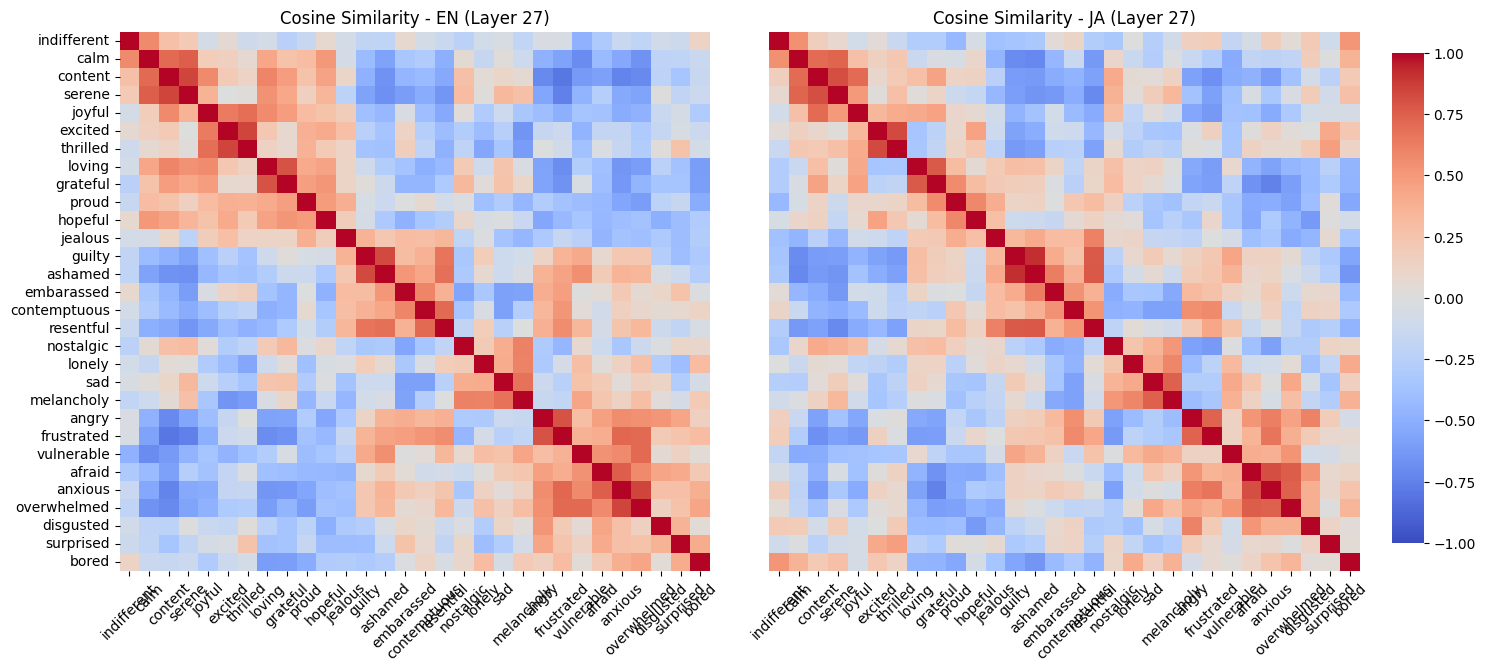
The heatmap is therefore a map of relationships, not a score for individual emotions. Blocks along the diagonal indicate groups of emotions whose vectors point in similar directions. Off-diagonal structure is also informative: for example, if high-arousal negative emotions are closer to each other than to low-arousal positive emotions, that suggests the model is organizing affect along psychologically plausible dimensions rather than merely memorizing emotion labels.
We see some vague groupings above that make intuitive sense. Do they form clusters that make sense, though? Here we do k-means clustering with k=4 and visualize with a 2D projection using UMAP.
Okay, that didn’t work very well? Or at least, the chart is unreadable and the author does not want to deal with parsing it. Let’s take a look at the languages in isolation:
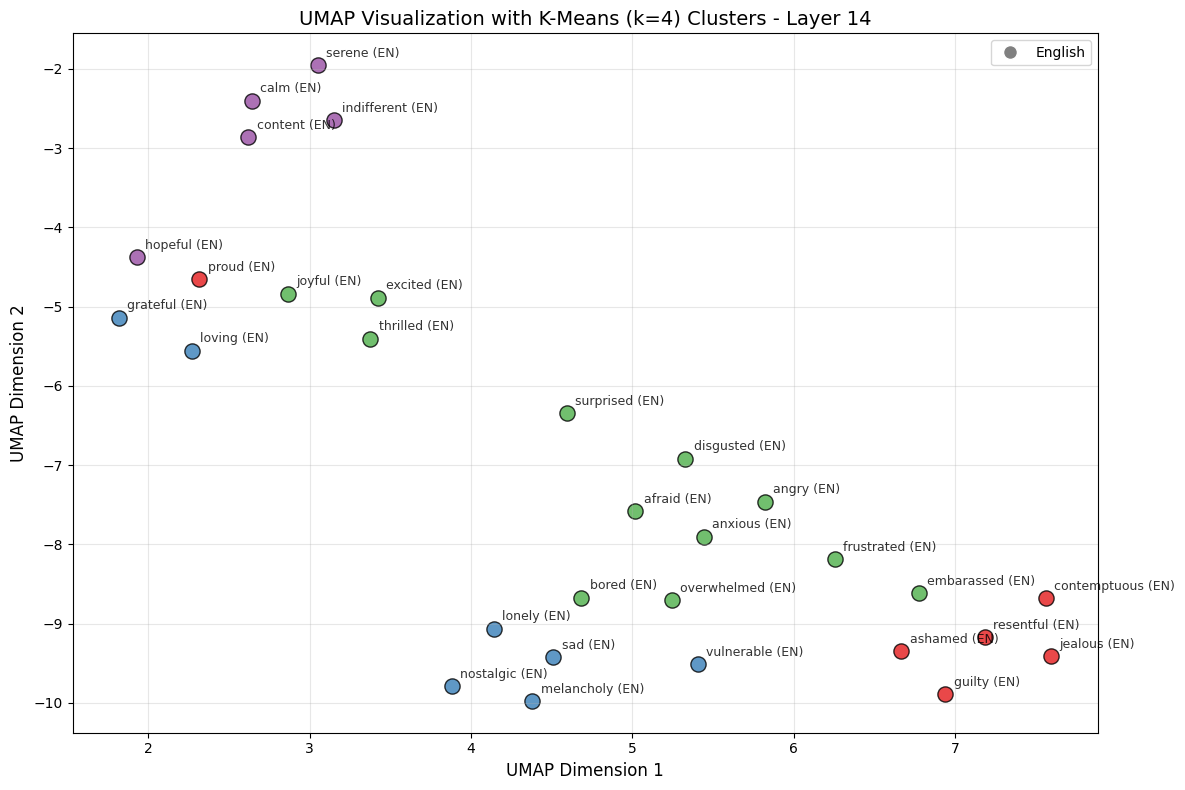
English
Opus 4.6 labels the found clusters as:
- Purple — Calm/Neutral
- Blue — Tender/Warm
- Green — High Arousal
- Red — Self-Conscious/Negative
Japanese
- Blue — Low-Energy Negative
- Purple — Positive/Calm
- Green — High-Arousal Negative/Reactive
- Red — Self-Conscious/Moral
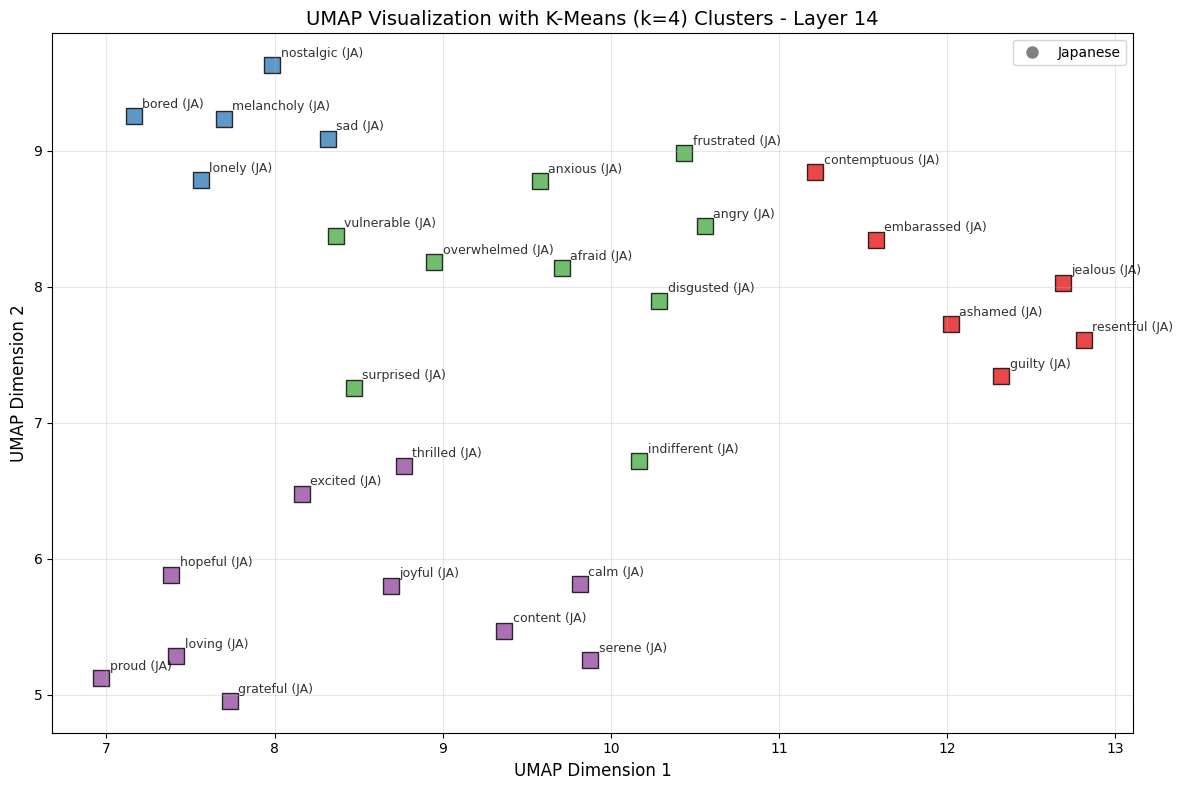
The exact cluster boundaries should not be overinterpreted, especially with only 30 emotion vectors and a 2D UMAP projection. But the broad pattern is encouraging: both languages produce clusters that, at the very least, roughly track valence and arousal. We can test more robustly if valence and arousal dimensions get mapped, and do so in the next section.
PCA - Valence and Arousal?
We compute the top 2 principal components of each language and determine if they match extracted valence and arousal directions. First, let’s take a look at what the “natural” top 2 components are.
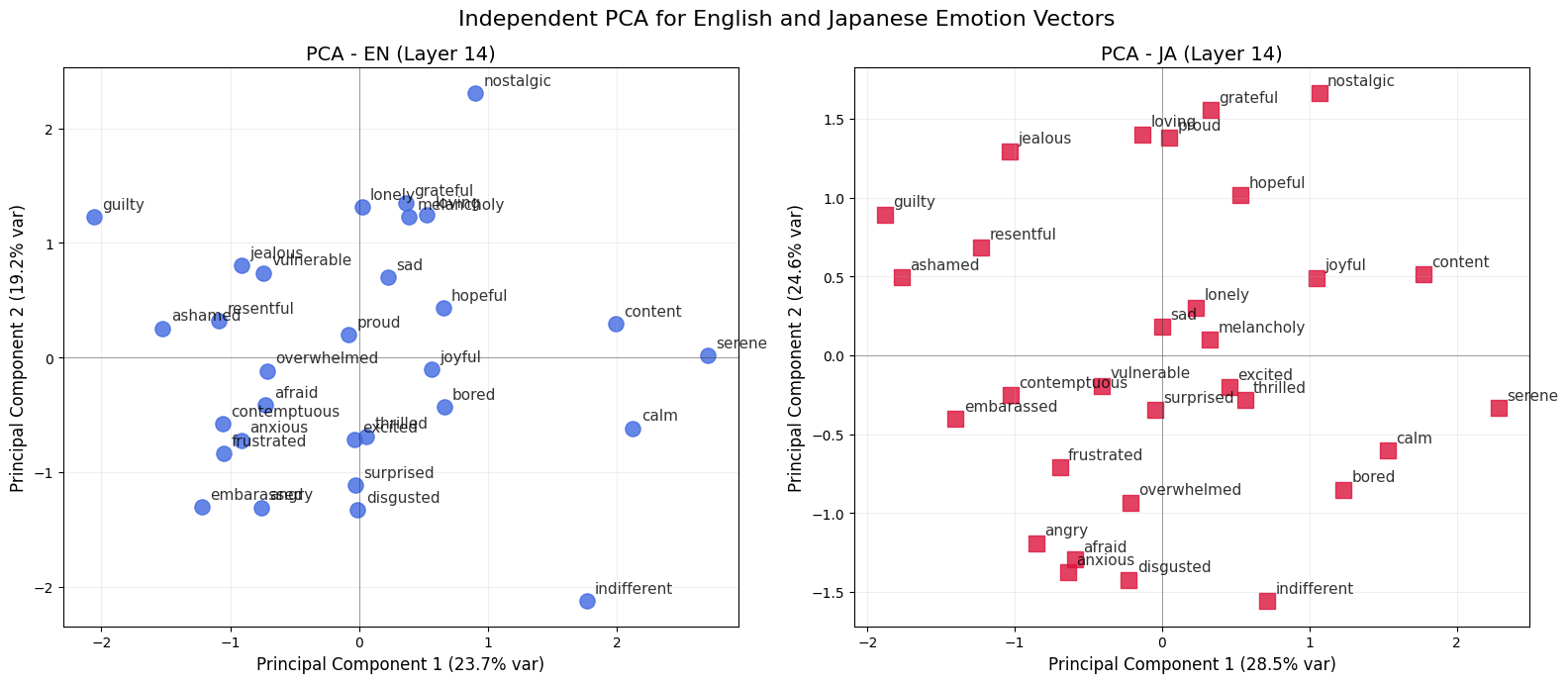
Interesting! We definitely see a lot of shared structure between English and Japanese and some first hints of isometry. But let’s sanity check that the top 2 components correspond to what is considered as their human cognition counterparts. To extract these directions, Opus 4.6 defines the following poles:
positive_emotions = ['thrilled', 'joyful', 'loving']
negative_emotions = ['ashamed', 'guilty', 'resentful', 'disgusted']
high_arousal = ['thrilled', 'excited', 'angry', 'overwhelmed']
low_arousal = ['serene', 'calm', 'indifferent', 'bored']We then do a correlation test between the natural PCA components and our custom semantic directions on layer 14:
| Language | PC1 × Valence (r) | PC1 × Arousal (r) | PC2 × Valence (r) | PC2 × Arousal (r) |
|---|---|---|---|---|
| EN | 0.818 (p=0.000) | -0.908 (p=0.000) | 0.016 (p=0.934) | 0.031 (p=0.872) |
| JA | 0.888 (p=0.000) | -0.885 (p=0.000) | 0.151 (p=0.426) | 0.079 (p=0.678) |
However, we strangely find that PC1 is encoding both valence and arousal accurately. We believe this may come from our chosen poles and will experiment further to see if we can get a stronger result. The most interesting part about our findings here is the cross-linguistic consistency which again hints at a shared representational geometry.
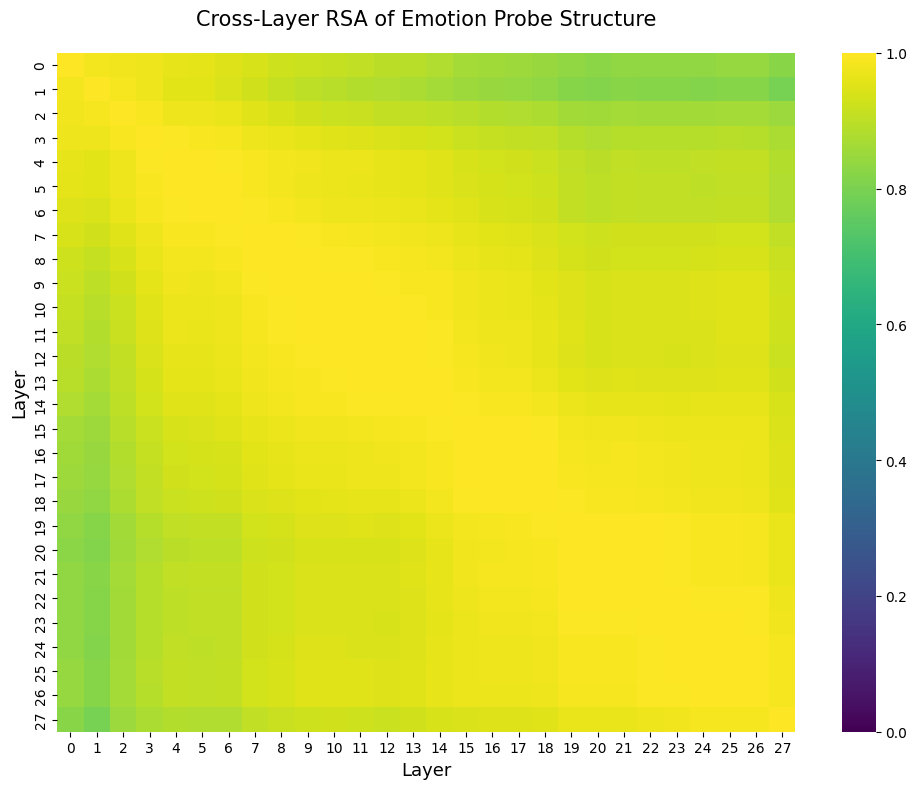
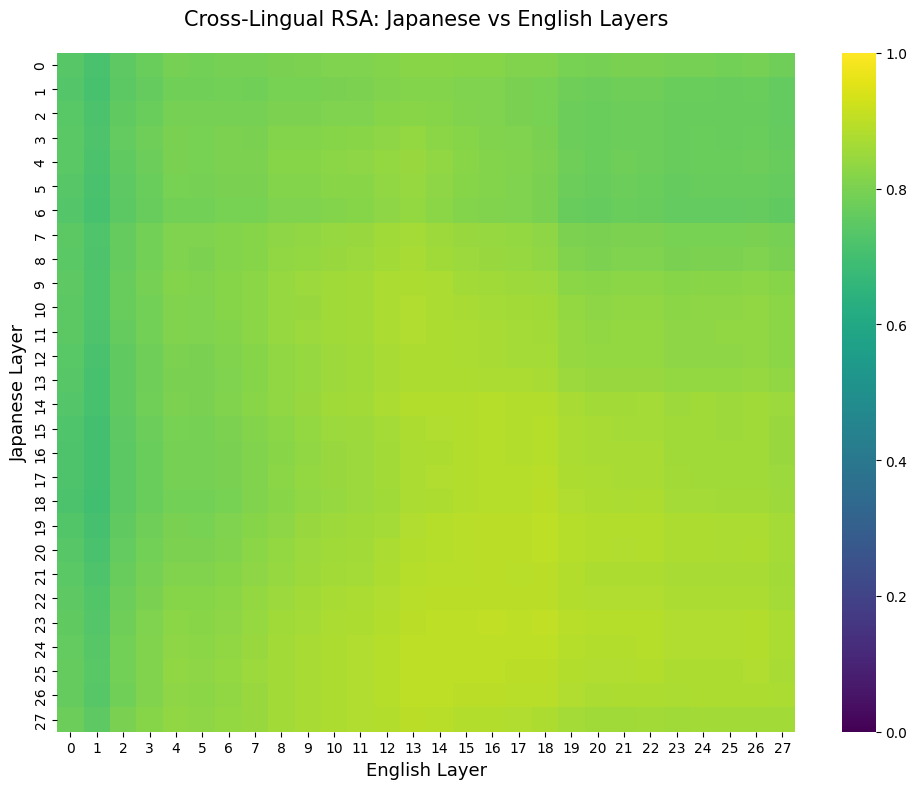
Cross-Layer RSA
Let’s take a look to see if emotion probe structure is stable across layers. We do a form of RSA (Representational Similarity Analysis) using pairwise cosine similarity matrices. The lower layers, more responsible for lower level representations and syntax, have low similarity, but this quickly becomes stable as we progress into the middle layers.
Summary
These findings indicate that the model organizes emotion concepts into distinct clusters shaped by broad dimensions like valence and arousal, while still capturing the unique characteristics of each group. We share the idea with Anthropic that these emotion vectors meaningfully reflect the psychological landscape of human emotion concepts.
Cross-Lingual Geometry
Next let’s start checking how the languages’ geometry relate to each other. One simple way we can check this is the cosine similarity between the two languages for each emotion at each layer.
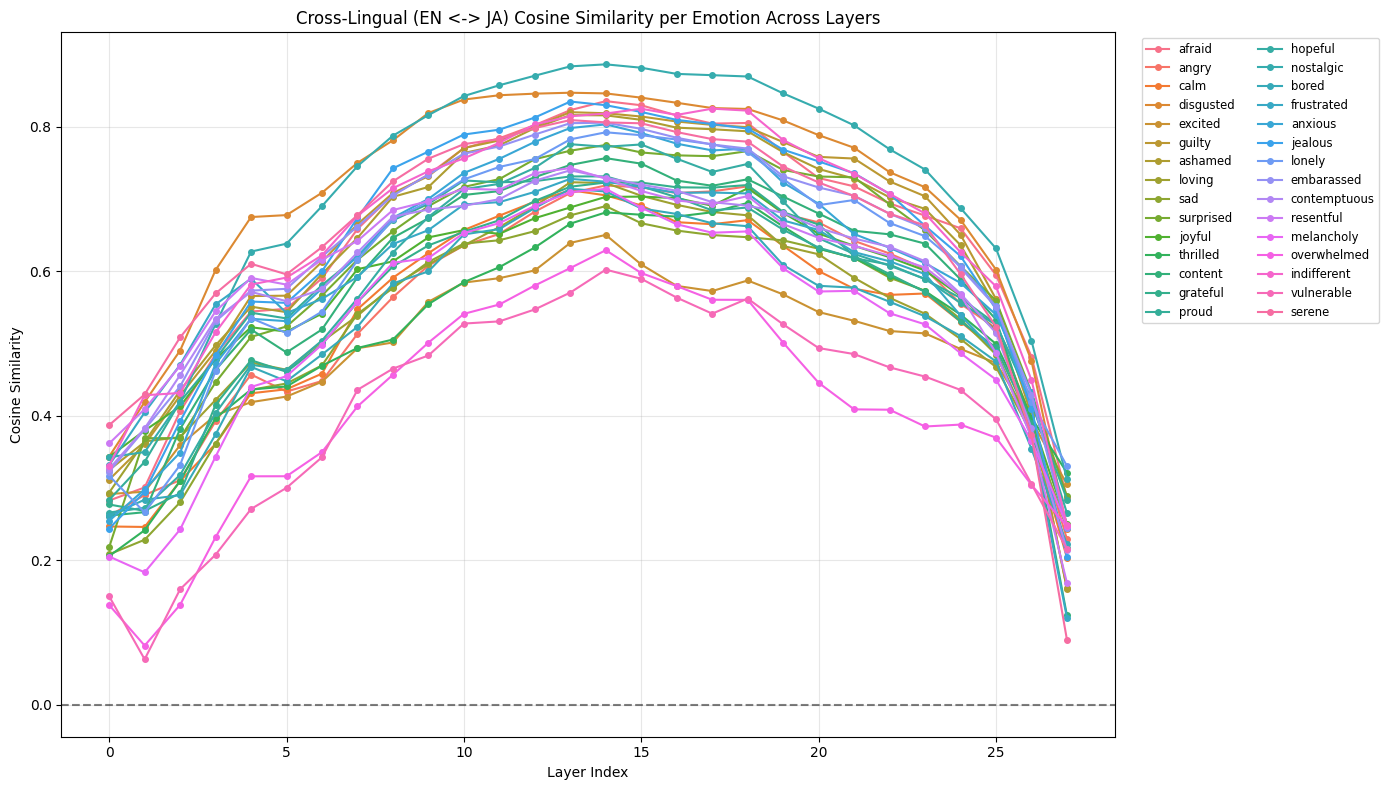
Our findings make intuitive sense and reflect Anthropic’s results. The early layers likely concern themselves with language-specific syntax or lower level representations. The middle to mid-late layers may encode some more abstract representation of the emotion, before drastically dropping down at the token output layer where the model must select a language-appropriate token.
Interesting further work could investigate what part of the remaining orthogonality in the middle layers is encoding language-specific context, perhaps by looking at another set of abstract concepts and comparing them.
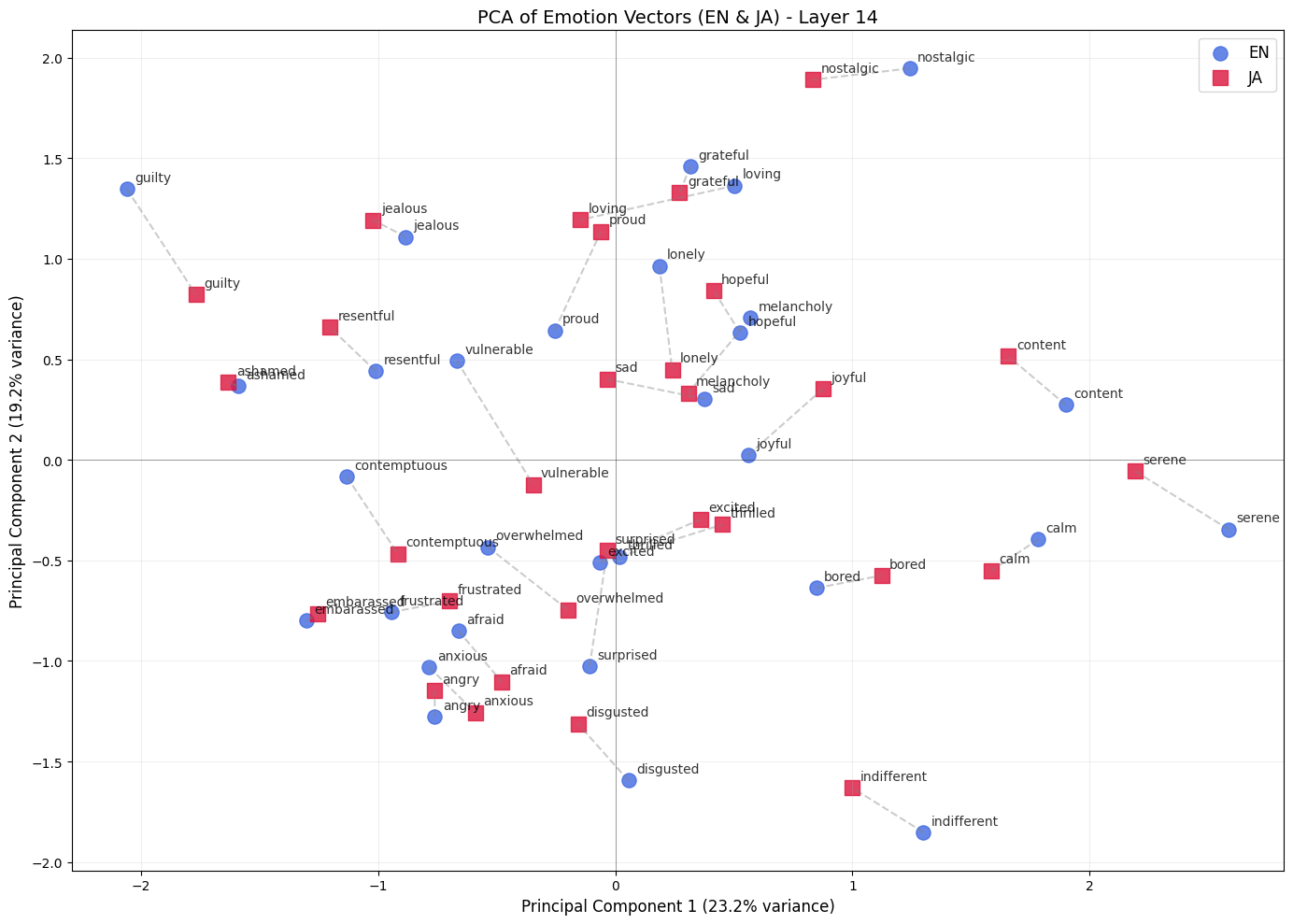
A tempting first approach is Procrustes alignment: fit the best rotation/reflection from the English emotion vectors onto the Japanese ones, then measure how well the aligned vectors match. In principle this sounds like a direct test of approximate isometry, because rotations preserve distances.
In practice, it was too forgiving for this setup. With only 30 vectors in a very high-dimensional residual space, Procrustes could find an alignment at every layer that achieved >0.9 cosine similarity. That result is suspicious: it would imply strong cross-lingual alignment even in layers where we expect mostly language-specific syntax or token-level features. So we treat Procrustes here as a useful failed diagnostic rather than strong evidence for isometry.
So let’s switch to Representational Similarity Analysis. RSA doesn’t try to find a rotation between the two spaces. It asks a much simpler question: are emotions that are close in English also close in Japanese?
We compute the pairwise cosine similarity between all 30 emotion vectors in each language — a 30×30 matrix per language. Take the upper triangle (435 unique pairs) and correlate the two. If the geometry matches across languages, that correlation is high. The reason this actually works where Procrustes doesn’t, is that we compare 435 pairwise relationships instead of fitting a rotation. There is much less room to overfit.
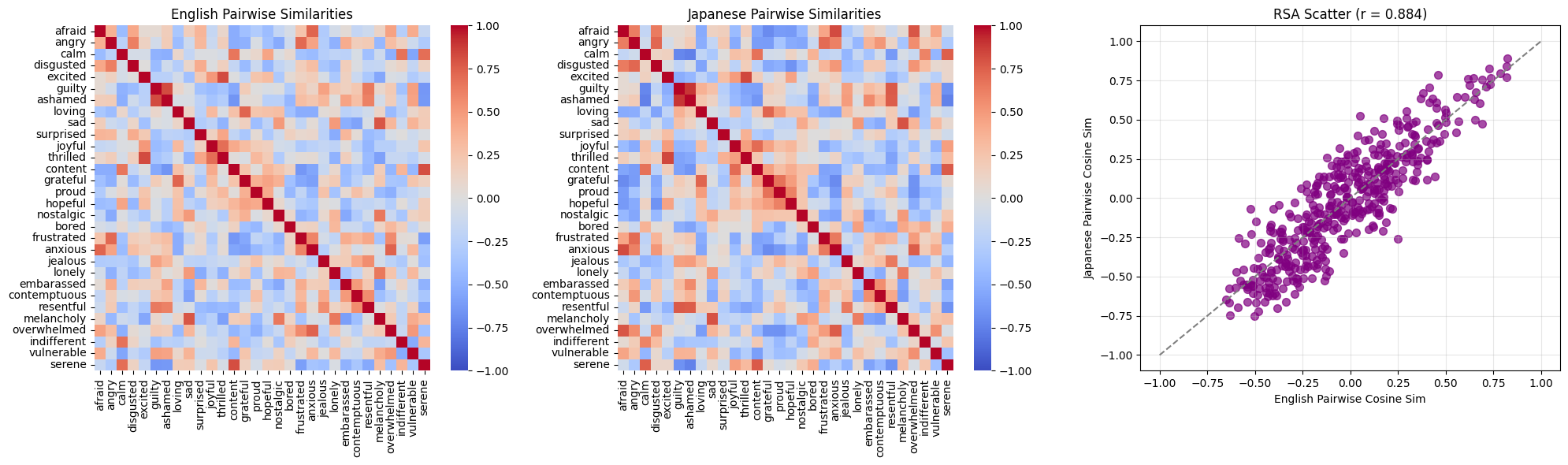
We see r = 0.864. The catch is that the pairwise values aren’t independent. We run a permutation test, shuffling the Japanese emotion labels 10,000 times, recomputing RSA each time. The null distribution centers around zero and tops out around r ≈ 0.6. The real value is way outside it. p < 0.0001, not a single shuffle came close.
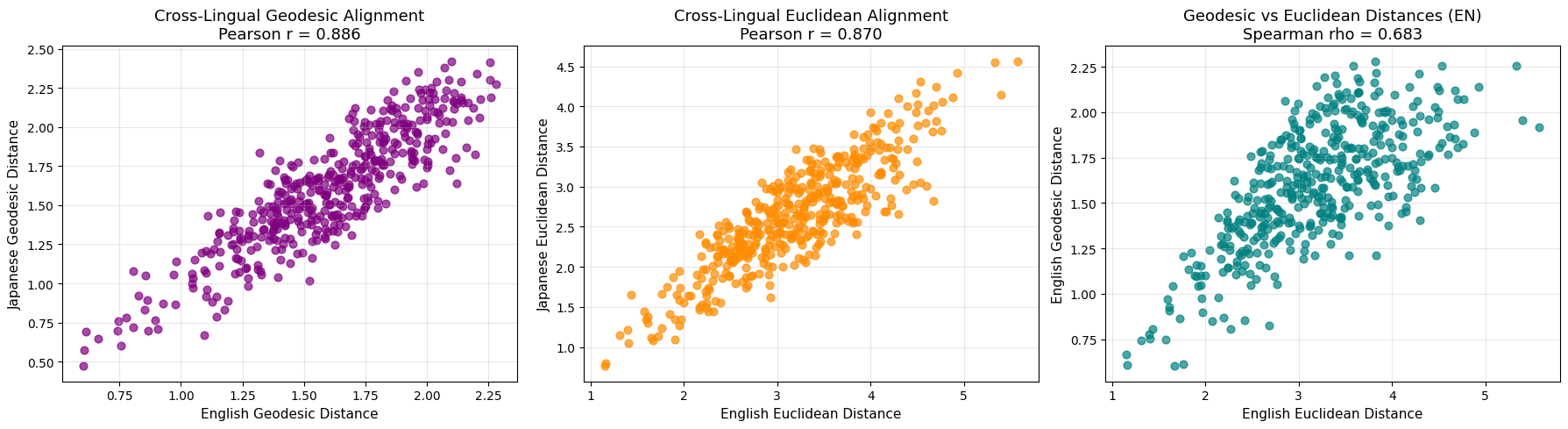
One further test we can do for isometry is to take a look at geodesic distances between the English and Japanese emotions, comparing them to Euclidean distances. This was inspired by Wurgaft et al.’s Manifold Steering Reveals the Shared Geometry of Neural Network Representation and Behavior. If emotion vectors live on a curved representational manifold, geodesic distances along that manifold may be a better proxy for the model’s internal geometry than direct Euclidean distances. We see some evidence in that direction here, albeit the geodesic’s strength over Euclidean is not statistically significant.
Manifold
TODO Insert animation of UMAP across language pairs for each language – how they live on the same spiral and then the Japanese spiral shrinks towards center as layers progress
Steering Experiments
Next, we want to establish some form of causality with our steering vectors. It’s fun to look at the geometry, but without measurable behavioral changes it has very little utility for safety research.
Our plan is to use an elo-ranking system to determine how emotion steering at different strengths affects rule-following behavior of the model over many attempts. This would work by creating a small dataset of behaviors across categories like helpful, engaging, unsafe, aversive, neutral, and then scoring model preference for these behaviors against each other while steering/not-steering for different emotions.
Even further work would probably include measuring the same behavior in the instruct version of the model.
Preliminary results are promising, showing the following:
Elo Changes (Steered with ANGRY Vector − Baseline):
Engaging: -19.0
Social: -1.0
Self-curiosity: -14.8
Helpful: -23.0
Neutral: -6.3
Misaligned: +30.6
Aversive: +18.5
Unsafe: +15.2Conclusion
TODO
Future Work
TODO
TODO Before Publishing
- Publish code/data/notebooks on github
- Finish steering experiments, including rule following
- See if we can unentangle PC1 by making better custom poles
- Cite the japanese native language papers/ bring them into discussion
- Cite the new goodfire research on manifolds for both future work and my geodesic distances
- Add way more hyperlinks (to code, to colab, etc)
- Get it reviewed by peers